
powermem
Build Persistent Memory for AI Applications
AI Infra开发者工具
16 喜欢16
3 评论3
8个月前发布
应用截图
1/3

2/3

3/3
使用场景
这是一款专为 AI 应用打造的智能记忆 SDK,通过 LLM 自动从对话中提取关键事实,实现记忆的去重、更新与合并,并基于艾宾浩斯遗忘曲线引入时间/频次的强化学习机制,让 AI 能像人类一样自然“遗忘”过时噪声信息。支持多智能体记忆共享和隔离、多模态(文本、图像、语音)记忆。
开发者/推荐人

PowerMem
开发者北京市

小小靖
开发者北京市
用户评论 (3)
发表评论
PowerMem
想象一下,你每天与AI助手对话,告诉它你的偏好、工作习惯、重要信息。第二天再聊,它却像第一次见面,需要你重复说明。这种体验在AI应用中很常见。这限制了AI应用的实用价值。
当前市场上的AI应用缺乏有效的记忆管理机制,主要表现为:
简单缓存:仅存储最近几轮对话,无法建立长期记忆
固定规则:基于预设规则提取信息,缺乏智能性
无上下文感知:无法根据当前对话内容智能选择相关记忆
无记忆优化:所有信息同等对待,未考虑记忆的时效性和重要性
这就是PowerMem的诞生背景——一个旨在解决AI应用中记忆问题的轻量级组件。
PowerMem
PowerMem建立在这样一个原则之上:AI系统应该能够像人类一样随着时间积累知识和经验。这一理念驱动了PowerMem设计和实施的每个方面:
● 智能提取和保留:PowerMem通过 LLM 模型进行记忆的提取,根据重要性和相关性确定哪些信息值得记住。
● 上下文理解:PowerMem维护跨交互的上下文以实现有意义的个性化体验。
● 持续学习:PowerMem使AI系统能够从每次交互中学习并随着时间的推移而改进。
● 自适应遗忘:像人类记忆一样,PowerMem实现了自适应遗忘机制以防止信息过载。
PowerMem
为什么需要 PowerMem?
上下文腐化问题告诉我们:不是模型记不住,而是我们喂错了东西。
PowerMem 的核心逻辑是:
● 提纯:从海量对话中提取高价值事实
● 压缩:去掉冗余,降低 token 成本
● 精准投放:把最关键的信息放在模型最容易注意到的位置
这本质上就是数据工程:
● 提取 = ETL
● 压缩 = 数据归档
● 投放 = 索引策略
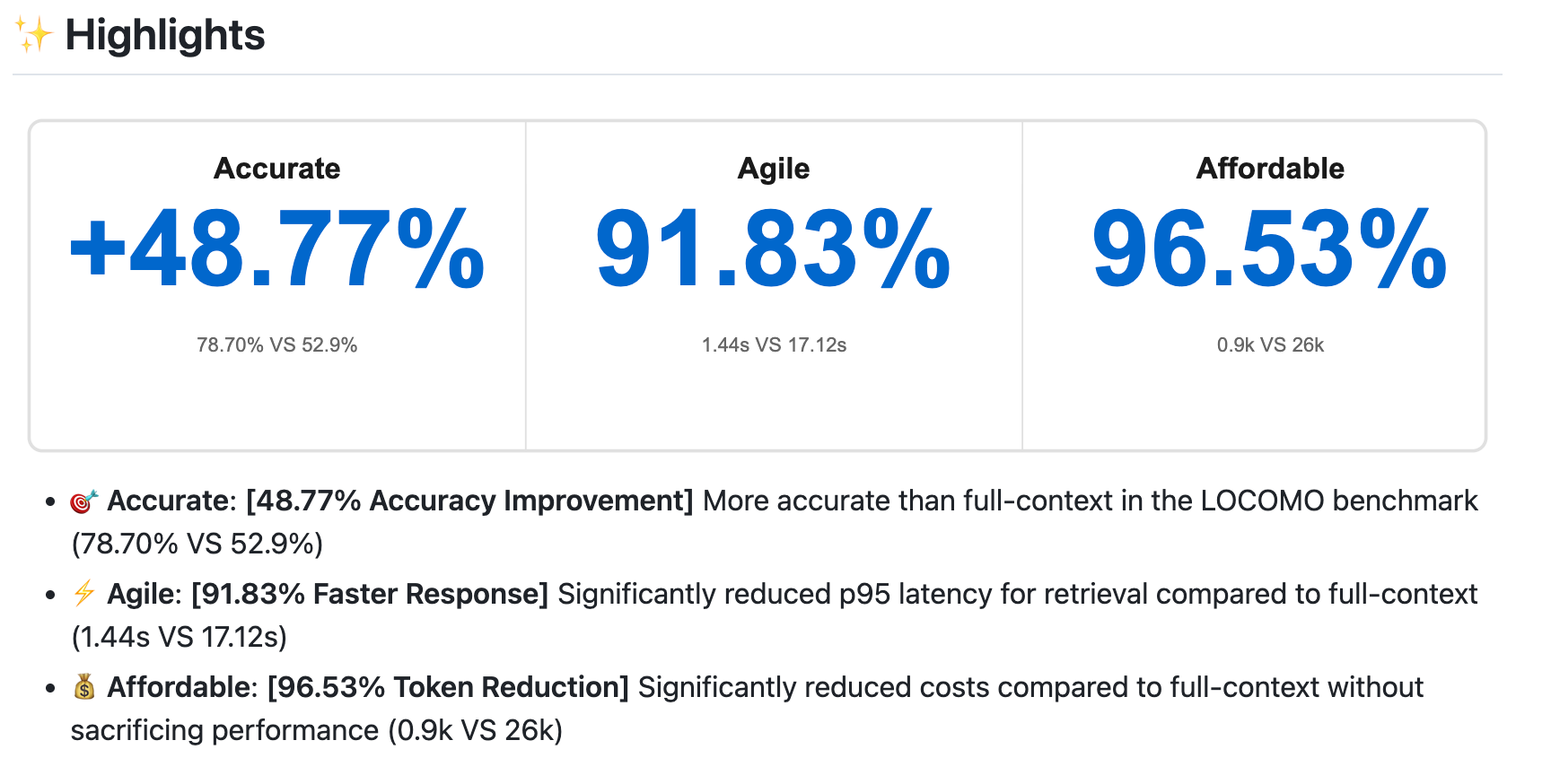
PowerMem 在 LOCOMO 基准测试中实现了:
● 准确率提升 48.77%(78.70% VS 52.9%)
● 响应速度提升 91.83%(1.44s VS 17.12s)
● Token 用量降低 96.53%(0.9k VS 26k)