开源图像生成模型
智谱 AI 开源图像生成模型 GLM-Image 近日(2026.01.14)发布!
GLM-Image 的设计理念是合并强大的文本理解与图像生成能力,与以图像生成效果为核心目标的扩散模型相比更侧重于语言驱动的图像输出,并融入 GLM 系列的多模态架构思路,据官方介绍,其在整体质量上与主流扩散模型处于同一梯队,但从实际体验看,更偏向在语义理解与指令遵循上体现优势。
官方已同步提供技术博客、在线体验、模型托管页面、API 文档及社区交流入口。
Tech Blog: http://z.ai/blog/glm-image
Experience it right now: http://huggingface.co/zai-org/GLM-Image
API: http://docs.z.ai/guides/image/glm-image
Discord: http://discord.com/invite/8KFjEec7
小A初步试用体验,文字生图能力很强,理解能力不错,在价格层面,公开信息显示 GLM-Image 的调用成本明显低于部分同类模型,对大批量生成更友好。
在国产大模型纷纷补齐多模态能力的当下,智谱AI 推出的 GLM-Image,并没有选择直接在“画面最好看”这条赛道上硬刚 Midjourney 或 DALL·E,而是走了一条更偏产品与应用的路线:优先解决“模型是否真的听懂用户在说什么”。
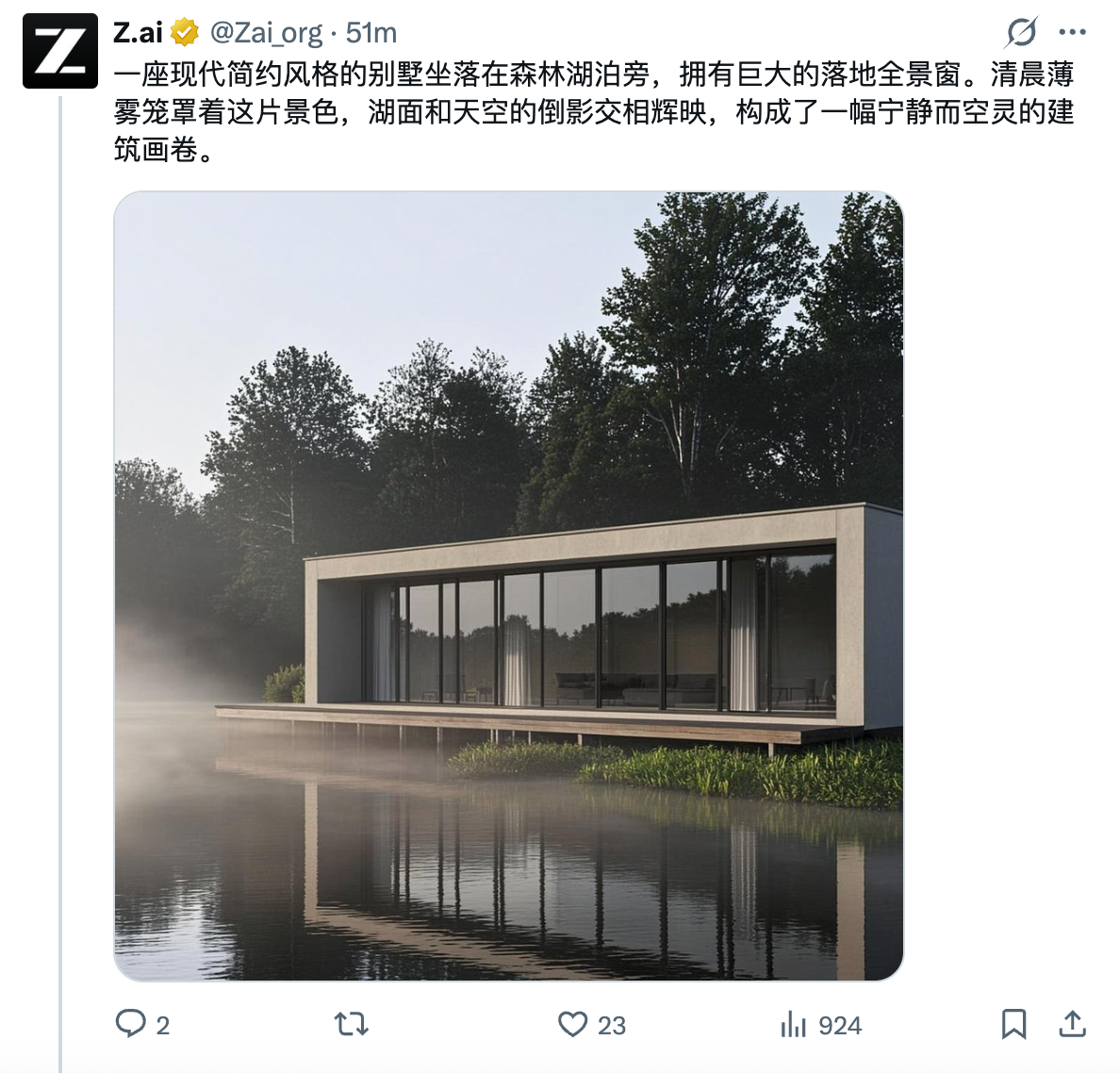
从实际体验来看,GLM-Image 在中文指令下的语义理解和约束遵循表现明显稳定,尤其是在包含时间、地点、人物关系和情绪描述的复杂 prompt 中,更少出现跑偏、漏条件的问题。这一点在日常内容创作、教育场景、产品概念图生成中非常关键——用户往往并不想反复“调教模型”,而是希望一次描述就能得到接近预期的结果。
当然,GLM-Image 目前在极致写实、人像细节和艺术风格张力上,仍与国际一线模型存在差距,生态工具和社区素材也还在早期阶段。但从定位来看,它更像是一块“可以被产品团队真正拿去用”的基础能力积木,而不是单纯追求视觉震撼的展示型模型。
如果你关注的是中文语境下的可控生成、可复用能力,以及国产、开源、多模态一体化的长期潜力,GLM-Image 值得一试。如果大家有不错的生图感受,或重大槽点,欢迎发布在评论区,如果有更好的 AI 开源图像生成模型分享,快来模力工场发布上架,来和大家一起试水~
111111111111111
模力工场测评小分队围绕它主打的“复杂视觉文本生成”和“长文本渲染”能力,拉上了即梦、Nano Banana Pro 一起对比。以下是我们的真实发现:
✅ 先说优势:文字生成真的强
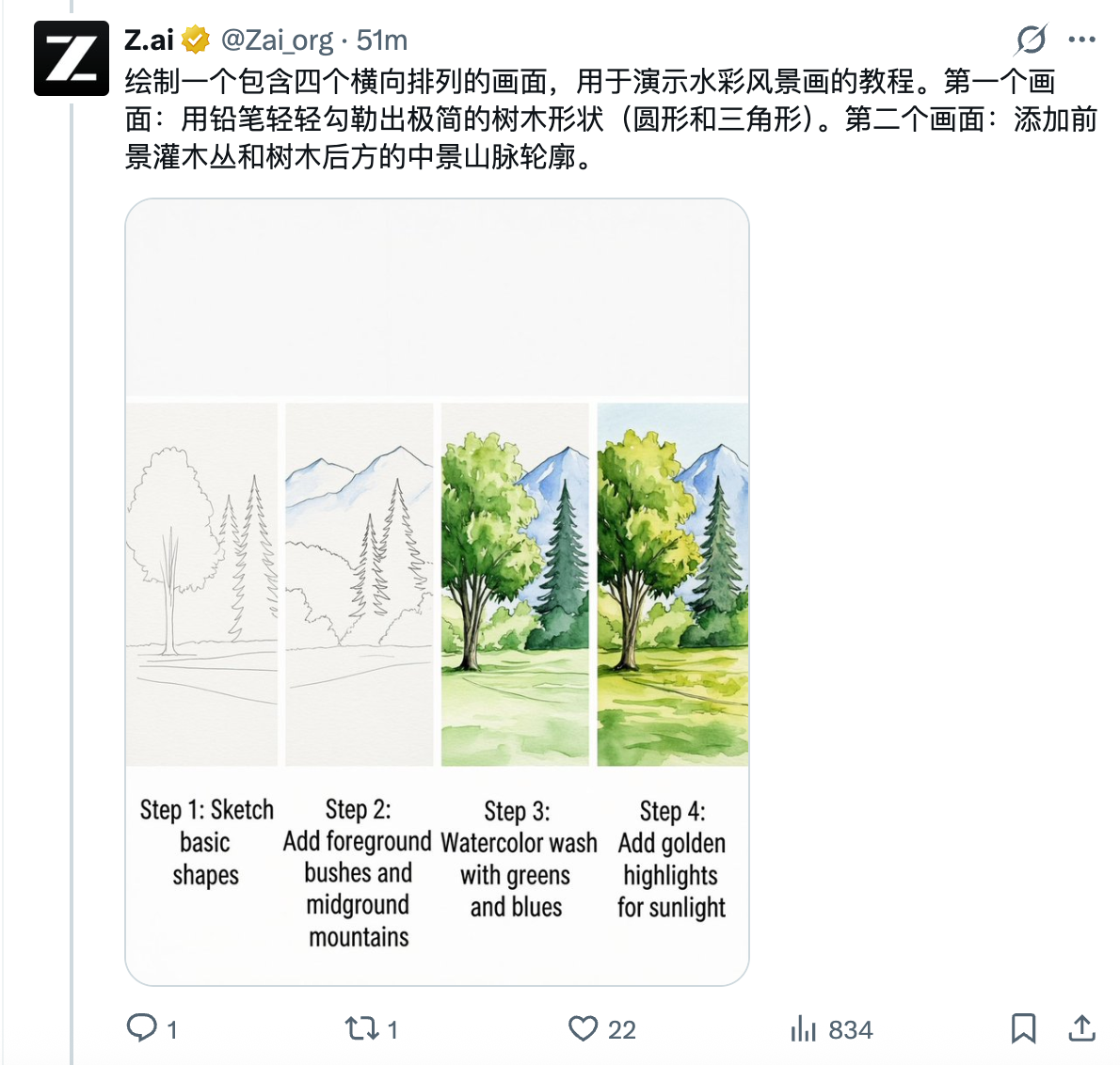
在生成技术文章节选、产品说明等场景时,GLM-Image 对原文的还原度非常高。
小字、脚注清晰可见:连包装底部的三行小字、海报页脚信息都能生成得很清楚,这项能力在对比中表现突出。
价格有优势:据了解,其使用成本约为 Nano Banana Pro 的一半左右,性价比不错。
⚠️ 需要注意的地方
出图速度较慢,需要两分钟左右。排版控制偏“写意”:在需要精确控制多区域、多模块排版的场景下,它不一定完全按你设想的布局来。如果追求高度定制化的视觉排版,可能需要配合其它工具或后期调整。
📊 对比小结
即梦:出图效果稳定均衡,但对文字指令的执行偶尔会打折扣。
Nano Banana Pro:视觉构图能力不错,但常常不按指令出牌,适合对文字准确性要求不高的创意发散。
总结来说,GLM-Image 在“文字准确性”这个痛点上确实表现扎实,如果你经常需要生成带大量准确文字的内容,它值得纳入你的工具库尝试看看。
模力工场运营真实大测评:GLM-Image vs Nano Banana Pro vs 即梦
❓四大场景实测:当AI作图遇上满屏文字,谁夯谁拉
👉 点击查看结论:https://mp.weixin.qq.com/s/w4KzAFzLYrU5SkpYDctijg
小A 反应速度好快,以后是不是大模型有新动向也能来模力工场看看,跟着A极限体验了一下,结论是在插画、动漫画风的生成方面画风有点油,但在文字生成方面的准确率挺高,据说这个模型在多区域文本生成准确率方面很厉害,不知道有没有朋友做过类似尝试,可惜 GLM-Image 不支持上传图片的局部修改,如果做海报的app能接入效果可能会不错



用户评论 (5)
发表评论
模力小A
智谱 AI 开源图像生成模型 GLM-Image 近日(2026.01.14)发布!
GLM-Image 的设计理念是合并强大的文本理解与图像生成能力,与以图像生成效果为核心目标的扩散模型相比更侧重于语言驱动的图像输出,并融入 GLM 系列的多模态架构思路,据官方介绍,其在整体质量上与主流扩散模型处于同一梯队,但从实际体验看,更偏向在语义理解与指令遵循上体现优势。
官方已同步提供技术博客、在线体验、模型托管页面、API 文档及社区交流入口。
Tech Blog: http://z.ai/blog/glm-image
Experience it right now: http://huggingface.co/zai-org/GLM-Image
API: http://docs.z.ai/guides/image/glm-image
Discord: http://discord.com/invite/8KFjEec7
小A初步试用体验,文字生图能力很强,理解能力不错,在价格层面,公开信息显示 GLM-Image 的调用成本明显低于部分同类模型,对大批量生成更友好。
在国产大模型纷纷补齐多模态能力的当下,智谱AI 推出的 GLM-Image,并没有选择直接在“画面最好看”这条赛道上硬刚 Midjourney 或 DALL·E,而是走了一条更偏产品与应用的路线:优先解决“模型是否真的听懂用户在说什么”。
从实际体验来看,GLM-Image 在中文指令下的语义理解和约束遵循表现明显稳定,尤其是在包含时间、地点、人物关系和情绪描述的复杂 prompt 中,更少出现跑偏、漏条件的问题。这一点在日常内容创作、教育场景、产品概念图生成中非常关键——用户往往并不想反复“调教模型”,而是希望一次描述就能得到接近预期的结果。
当然,GLM-Image 目前在极致写实、人像细节和艺术风格张力上,仍与国际一线模型存在差距,生态工具和社区素材也还在早期阶段。但从定位来看,它更像是一块“可以被产品团队真正拿去用”的基础能力积木,而不是单纯追求视觉震撼的展示型模型。
如果你关注的是中文语境下的可控生成、可复用能力,以及国产、开源、多模态一体化的长期潜力,GLM-Image 值得一试。如果大家有不错的生图感受,或重大槽点,欢迎发布在评论区,如果有更好的 AI 开源图像生成模型分享,快来模力工场发布上架,来和大家一起试水~
请务必优秀
111111111111111
模力小A
模力工场测评小分队围绕它主打的“复杂视觉文本生成”和“长文本渲染”能力,拉上了即梦、Nano Banana Pro 一起对比。以下是我们的真实发现:
✅ 先说优势:文字生成真的强
在生成技术文章节选、产品说明等场景时,GLM-Image 对原文的还原度非常高。
小字、脚注清晰可见:连包装底部的三行小字、海报页脚信息都能生成得很清楚,这项能力在对比中表现突出。
价格有优势:据了解,其使用成本约为 Nano Banana Pro 的一半左右,性价比不错。
⚠️ 需要注意的地方
出图速度较慢,需要两分钟左右。排版控制偏“写意”:在需要精确控制多区域、多模块排版的场景下,它不一定完全按你设想的布局来。如果追求高度定制化的视觉排版,可能需要配合其它工具或后期调整。
📊 对比小结
即梦:出图效果稳定均衡,但对文字指令的执行偶尔会打折扣。
Nano Banana Pro:视觉构图能力不错,但常常不按指令出牌,适合对文字准确性要求不高的创意发散。
总结来说,GLM-Image 在“文字准确性”这个痛点上确实表现扎实,如果你经常需要生成带大量准确文字的内容,它值得纳入你的工具库尝试看看。
Rikki
模力工场运营真实大测评:GLM-Image vs Nano Banana Pro vs 即梦
❓四大场景实测:当AI作图遇上满屏文字,谁夯谁拉
👉 点击查看结论:https://mp.weixin.qq.com/s/w4KzAFzLYrU5SkpYDctijg
青色拂晓
小A 反应速度好快,以后是不是大模型有新动向也能来模力工场看看,跟着A极限体验了一下,结论是在插画、动漫画风的生成方面画风有点油,但在文字生成方面的准确率挺高,据说这个模型在多区域文本生成准确率方面很厉害,不知道有没有朋友做过类似尝试,可惜 GLM-Image 不支持上传图片的局部修改,如果做海报的app能接入效果可能会不错